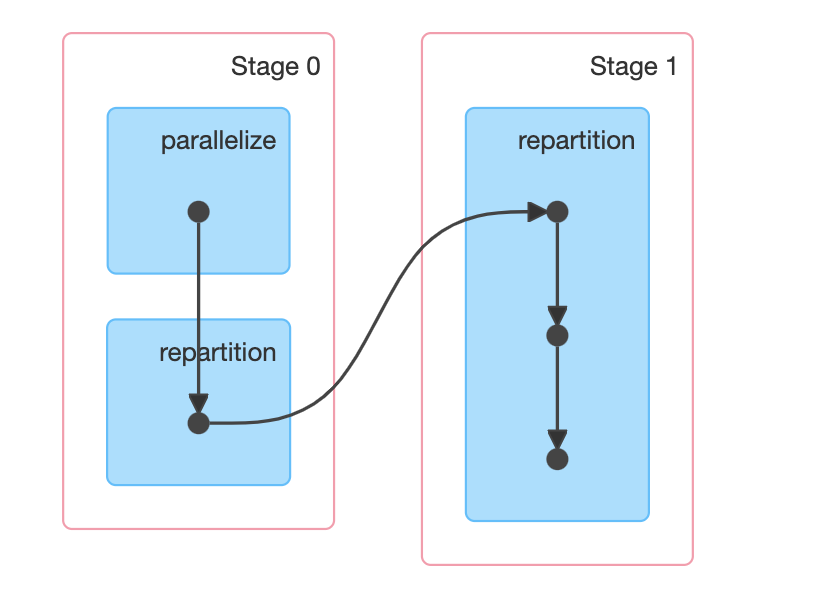
Building DataLakes can become complicated when dealing with lots of data. Even more so, when working with heavily skewed data. In this post, we'll be looking at how we can improve your long running Spark jobs caused by skewed data.